V10 特徵再工程計劃 — 總結白皮書
日期 2026-06-21
承接 V10.0 純 Benter 賠率盲基礎,論「能否以簡單特徵擊敗它」之窮舉嘗試與誠實負面結果
版本 V10.1 至 V10.6(特徵再工程計劃,2026-06-20 至 06-21) 基礎錨點 V10.0(特徵雜湊 bb6a8f58)
樣本外時段 A:2026-03-01 至 06-13(299 場);B:2025-09-01 至 2026-03-01(474 場);
乾淨保留時段 C:2025-03 至 09(382 場);D:2024-09 至 2025-03(465 場);E:2024-03 至 09(367 場)
本篇為 V10 系列的特徵再工程篇,承接已完成的《V10.0 基礎白皮書》。基礎篇奠定了系統的紀律、框架、數學與護欄;本篇則總結 V10.1 之後逐一測試的七個候選特徵,記錄它們在演進後的紀律閘下的最終裁決,並把校準、價值投注與 Benter 第二階段三項決定性實證一併收束,給出戰略層面的結論。全文數據皆源自 registry 與內部窮舉掃描結果,不經人手輸入。
1. 摘要
V10.0 基礎篇以九萬餘組參數的窮舉,確立了一個可重現、防洩漏、四機逐位元一致的純 Benter 賠率盲基線(棄用 XGB,加權勝 22.4% / 位 49.4%)。本篇回答其遺留的核心問題:能否以一個簡單的加性特徵擊敗這條基線?
答案是否定的。在演進後的紀律閘(配對逐場信賴區間、入位同時把關、選擇性洩漏意識、決定於乾淨保留的 C+D+E)下,七個候選特徵——draw_eb、trip、closer_pace、closer_turns、field_rating_adv、sectional_verdict、rating_delta——全部未獲晉升(0/7)。其中兩個(draw_eb、trip)重演「時段 A 改善、時段 B 失分」的海市蜃樓;其餘五個的乾淨集勝率增量皆落在 ±1 個百分點以內、統計上與零無異。本篇同時報告三項決定性實證:(一)模型已校準良好,期望校準誤差(ECE)僅 0.23%,無需校準;(二)賠率盲模型的「價值」投注在幾乎整個格點上皆虧損,冷門高期望值組別蝕 48% 至 60%;(三)Benter 第二階段擬合得基礎模型權重 β1 約等於零,意即 V10.0 相對市場無任何增量資訊。三者交匯於同一結論:V10.0 是「賠率盲+簡單特徵」這一類模型的天花板。 真正餘下的提升不在於再多一個特徵,而在於兩條岔路之間的戰略抉擇——更豐富的 Stage 1(唯一被證明能擊敗市場之路,但須打破賠率盲三腳架),或者運營化(預測網站與賽後認證)。本篇主張:這些「誠實的負面結果」本身極具價值,它們把資源從注定無功的方向上釋放出來。
2. 引言——基礎與核心問題
2.1 V10.0 的賠率盲基礎與三腳架原則
基礎篇把香港賽馬首選預測界定為場內排名問題:給定一場 N 匹馬,估計各馬勝出機率並選出首選。其核心是 Benter 條件邏輯回歸——每匹馬效用 Uᵢ = Σₖ βₖ xₖᵢ,場內以歸一化指數(softmax)得勝出機率 P(i 勝 | 場) = exp(Uᵢ) / Σⱼ exp(Uⱼ)。系統把所有「會變的東西」參數化為歷史/特徵/參數三層,以五元組 ReproKey 鎖定可重現性,並在四部 Intel 認證機上窮舉九萬餘組參數,得出穩健結論:在五個特徵下,XGB 為高方差學習器,淨負面;純 Benter 最優(構建 10.0.3:時段 A 勝 24.75 / 位 51.84,時段 B 勝 20.89 / 位 47.89,加權勝 22.38% / 位 49.42%)。
其中一條不可違背的紀律是賠率盲(odds-blind):模型機率不得偷看賠率。這源自 Eric 的三腳架原則——模型、Eric、賠率是三條相互獨立的腳;模型若偷看賠率,這條腳便塌進市場,與市場那條腳合二為一,三腳架隨即坍塌。賠率只在第二階段(期望值/投注)使用。本篇貫徹此原則,所有特徵實驗皆在賠率盲前提下進行。
2.2 核心問題:能否擊敗它
基礎篇明言:參數空間已最優,進一步增益須靠特徵工程而非參數。它亦留下一個尚未閉合的疑問——基礎篇結尾的 draw_eb 已通過防洩漏與重現性測試,卻在兩窗閘被否決(時段 A 改善、時段 B 失分),這究竟是個別失敗,還是一整類嘗試的通病?
本篇即以「一次只變一個變量、窮舉→學習→結論→記錄」的紀律,逐一回答:在這個五特徵純 Benter 基線之上,加入一個簡單的加性特徵,能否在嚴謹的多窗、防洩漏、防選擇偏差的閘下,穩健地擊敗它?
3. 方法——紀律閘的演進
V10.0 的兩窗閘(時段 A 與 B 皆須不失分)是本系統紀律的首個實證武器。但在特徵再工程過程中,一場對抗性審查揭示這道閘力有不逮,逼使紀律閘自身經歷一次關鍵演進。本節記錄這次演進,它是理解第 4 節「全部不顯著」裁決的前提。
3.1 兩時段閘的局限:統計效力不足
對抗性審查指出三個結構性問題:
第一,我們一直在雜訊底之下作裁決。 299 場(時段 A)的勝率標準誤約為 2.4 個百分點,而候選特徵的增量(如 closer_turns 的 +0.26pp)比它小一個數量級。直接比較兩個約 22% 的原始聚合勝率,根本無法分辨任何低於 2pp 的移動。
第二,選擇性洩漏。 時段 A+B 正是當初九萬餘組窮舉掃描的評分窗,而那次掃描同時選出了「純 Benter」與 closer_turns。換言之,A 與 B 對於模型形態的選擇而言已屬樣本內;再以它們充當晉升閘的「樣本外」仲裁,是受污染的。
第三,已編碼的閘只把關勝率(win-only)。 它只要求勝率不退步,入位率僅印出而不把關,這會默默放行「勝率升、入位率跌」的特徵,侵蝕「勝率與入位率並重」的標準目標。
3.2 演進後的紀律閘(gate.py)
針對以上三點,系統建立了新的標準閘 gate.py,具備四項特性:
- 配對逐場信賴區間。 不再比較兩個原始聚合勝率,而是對同一批場次作配對的逐場檢定(麥內瑪/McNemar 式),給出一個必須排除零的信賴區間。由於兩個模型在絕大多數場次選出相同的首選,配對的標準誤遠小於聚合標準誤,效力因此大幅提升。
- 乾淨保留 C+D+E 為唯一仲裁。 把受選擇污染的 A+B 降為「對照報告」,把從未參與模型形態選擇的 C、D、E(合共約 1,214 場)列為唯一乾淨仲裁,並對它們設預算,不在每個候選上重複消耗。
- 入位同時把關。 通過條件改為「勝率顯著為正 且 入位率不顯著退步」,堵住勝升位跌的漏洞。
- 選擇性洩漏意識。 明確區分「為選模型形態而用過的窗」與「乾淨保留窗」,裁決只認後者。
3.3 統計效力的硬限制
這道演進後的閘揭露了一個無法迴避的事實:以目前約 1,200 至 2,000 場的樣本外規模,只能分辨約 1 個百分點以上的效應。任何低於 1pp 的增量,無論方向如何,都落在數據的解析度之下,統計上與零無異。這一限制是第 4 節全部七個特徵裁決的共同背景:它們的乾淨集增量無一達到 1pp。
此外,本系統沿用基礎篇的全套護欄:結構性防洩漏(累加器逐場後更新、新特徵須通過「截斷歷史」單元測試)、種子穩定性、空假設底線,以及對首選 argmax 的有種子隨機破同分——後者是為了根絕「賽果列以完賽次序排列、穩定 argsort 會挑中冠軍」這個曾同時污染過往評估的洩漏陷阱。
4. 結果一·特徵:0/7
七個候選特徵在演進後的紀律閘下全數被否決。下表為總帳(乾淨集勝率增量、裁決):
| 特徵 | 構思 | 乾淨集勝率增量 | 裁決 |
|---|---|---|---|
draw_eb(10.1) |
檔位歷史勝率(經驗貝葉斯收縮) | 時段 A 升/B 跌的海市蜃樓 | ✗ |
trip(10.2) |
過彎外圈失地米數(弧長幾何) | 時段 A 升/B 跌的海市蜃樓 | ✗ |
closer_pace(10.3) |
後上×步速壓力 | 時段脆弱(A 跌 B 升) | ✗ |
closer_turns(10.3) |
後上×總彎角 | +0.25pp,不顯著 | ✗ |
field_rating_adv(10.4a) |
場內負磅班次位置 | −0.25pp,不顯著 | ✗ |
sectional_verdict(10.5) |
真衝/執位/受阻 | +0.08pp,不顯著 | ✗ |
rating_delta(10.6) |
班次走勢(升班/跌班) | −0.17pp,不顯著 | ✗ |
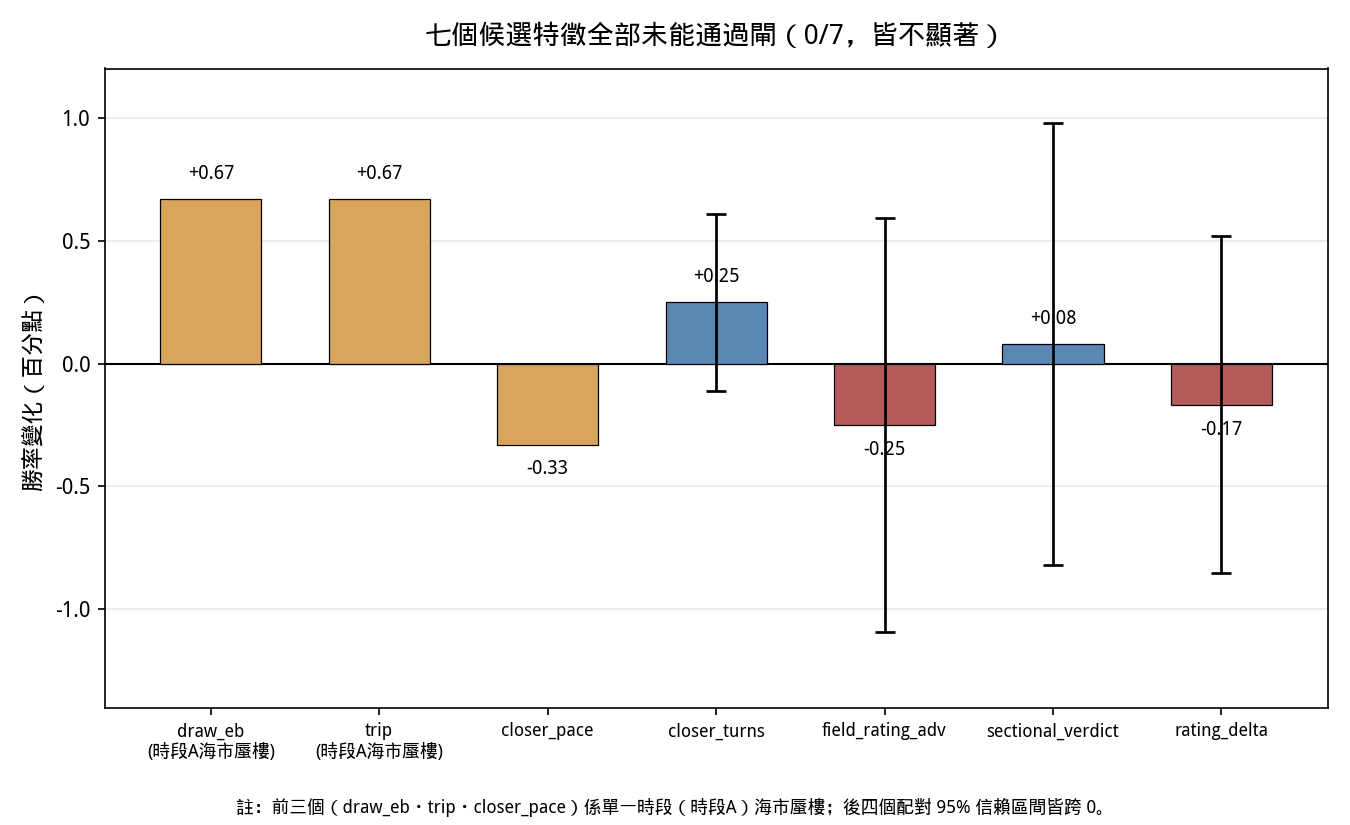
圖 1: 七個候選特徵的乾淨集勝率增量與其 95% 信賴區間總覽;每一條信賴區間皆跨越零,七者裁決一致為否(0/7)。
4.1 海市蜃樓:兩個檔位再編碼
draw_eb(V10.1)以真實歷史檔位勝率取代硬編碼的 draw_adv,採經驗貝葉斯貝塔-二項(Beta-Binomial)收縮、嚴格逐場即時計算(收縮強度 κ 為窮舉構建參數,故無擬合洩漏面)。它通過了截斷歷史洩漏測試,亦改善了時段 A(勝 +0.67、位 +1.33),卻在每一個 κ 值下都拖累時段 B(勝 −1.3 至 −1.5、位 −1.26)。這正是曾扼殺過往實戰嘗試的「時段 A 海市蜃樓/時段 B 失分」模式:場地×距離的檔位信號是近窗的人為產物,不能泛化。
trip(V10.2)以靜態賽道幾何把硬編碼檔位換成弧長失地米數,是純函數、天生防洩漏。它呈現與 draw_eb 完全相同的簽名:時段 A 改善(勝 +0.67、位 +1.33),時段 B 退步(勝 −1.06、位 −1.48)。共線性是線索——trip 與 draw_adv 相關係數 −0.73,與 field_norm_draw 相關係數 +0.75。它不過是把模型已承載的檔位軸重新編碼,沒有加入正交資訊,只能把同一條軸重新擬合到調校所用的那個窗。
兩個獨立而原理迥異的再編碼皆助 A 而蝕 B,這已不再是巧合,而是一個發現:平坦的、按馬計的檔位水平,在 V10.0 中已飽和;再編碼它無法增添穩健的樣本外邊際,只會產生窗特定的過擬合。 餘下的檔位信號(若有)不在水平本身,而在場層交互。
4.2 噪音底之下:五個低於解析度的特徵
其餘五個特徵——包括理論上最有希望的場層交互與班次走勢——皆敗於同一堵牆:效應太小,沉在數據的解析度之下。
closer_turns(V10.3,後上×總彎角,物主的過彎物理學)一度被記為計劃的首個正面結果:它在兩窗的原始讀數通過閘,且在五個獨立窗(合共約 1,987 場)勝率「五分之五不退步」(四正一平,平均約 +0.26pp)。但配對逐場顯著性檢定推翻了這個原始讀數:在乾淨保留的 C+D+E(n=1214),勝率增量 +0.247pp,95% 信賴區間 [−0.114, +0.608],跨越零;入位率增量 +0.082pp,信賴區間 [−0.402, +0.567],亦跨越零。在全部五個窗(n=1987),勝率增量 +0.252pp,信賴區間 [−0.044, +0.547],同樣跨越零。根本原因是:closer_turns 在全部 1,987 場中只改變了 9 場的首選(七增二減),在乾淨的 C/D/E 上只有 5 場——整個「+0.26pp」僅僅建立在淨約三至五場之上,遠低於數據解析度。確定性消去了種子噪音,卻消不去抽樣噪音。這正是「逐特徵研磨一直在雜訊底之下運作」的實證。closer_pace(後上×步速)則是時段脆弱:在 B 為真、在 A 易碎,二者同加更差於任一單獨加入(彼此稀釋)。
field_rating_adv(V10.4a,場內負磅班次位置)是首個由演進後標準閘裁決的特徵,並附帶一項數據質量修正:計劃原指的 decl_wt(895 至 1492 磅)實為馬匹體重,與班次關聯的是負磅 act_wt(約 113 至 135 磅),經量程煙霧檢查抓出後重建於 act_wt。其裁決:在乾淨 C+D+E(n=1214),勝率增量 −0.247pp,信賴區間 [−1.086, +0.592],不顯著(略負);入位率 +0.247pp,信賴區間 [−0.761, +1.256],弱正但不顯著。值得一記的是,此特徵的「槓桿有量級」——它在乾淨集重排了 27 個首選(十二增十五減),遠多於 closer_turns 的 5 個;可見「尋找重排更多的特徵」這個方法論轉向在機械上奏效,但重排的淨效果在勝率上是中性至負。受讓賽的負磅均衡機制大致有效,場內原始班次位置無法線性擊敗對手。同時須記:受污染的 A+B 單獨會把此特徵誤判為「顯著有害」(−0.906pp,信賴區間 [−1.664, −0.147],顯著為負),而乾淨保留集說它「中性」——這是「排除選擇污染窗」這條紀律的具體佐證。
最後兩個——sectional_verdict(V10.5,把每匹馬上仗以真實末段分段速度重新評為真衝/執位/受阻/符合,此乃舊 214 特徵模型無法吸收的信號)與 rating_delta(V10.6,班次走勢,跌班馬歷史上跑贏升班馬的軌跡信號)——理論上分別瞄準入位軸與軌跡信號,最終乾淨集勝率增量分別為 +0.08pp 與 −0.17pp,皆不顯著。
4.3 雙重發現:海市蜃樓與噪音底
第 4 節的合成發現有二。其一是海市蜃樓:任何只在單窗測試的特徵都會收進時段 A 的 +0.67 假象,而兩窗閘正確攔截;這是檔位再編碼的死因。其二是噪音底的發現:當特徵通過了海市蜃樓這一關,它們又撞上統計效力的硬限制——在目前的樣本外規模下,凡低於約 1pp 的增量皆無法與零分辨。七個候選無一逃脫這兩堵牆。
結論:在這個樣本外解析度下,沒有任何簡單的加性特徵能擊敗 V10.0。 V10.0(五特徵、純 Benter)就是模型本身。
5. 結果二·校準
既然加性特徵無法移動首選命中率,一個自然的猜想是:問題或許出在機率校準——若模型的機率系統性失準,則「價值」投注的虧損可歸因於校準偏差,而非模型本身。本節否證此猜想。
在約 38,000 個樣本外按馬預測上量度可靠度(calibrate.py),預測機率與實際勝率高度吻合:
| 預測機率 | 實際勝率 | 預測機率 | 實際勝率 | |
|---|---|---|---|---|
| 2.2% | 1.5% | 14.5% | 14.5% | |
| 4.0% | 4.2% | 20.9% | 20.8% | |
| 6.4% | 6.5% | 28.4% | 29.7% | |
| 9.8% | 9.7% | 38.6% | 39.2% |
期望校準誤差 ECE = 0.23%(極佳)。擬合所得溫度 T* = 0.95,約等於 1(無助益,驗證集 ECE 不變)。首選預測 21.3% 對實際 23.2%(輕微偏保守)。「期望值陷阱源於校準失準」的假設被否證——一匹模型評 6% 的馬,真的約六成之一機率勝出。
這帶來一條重要的負面推論:因為入位率在本系統中是首選 argmax 的入位率,而任何校準映射(溫度、普拉特/Platt、保序)在場內皆為單調,不能改變 argmax,故既不能移動勝率、亦不能移動入位率。校準唯一的真實槓桿在期望值/投注層與預測頁的信心/凱利注碼,絕不可當作命中率的提升手段。
校準不是下一步。
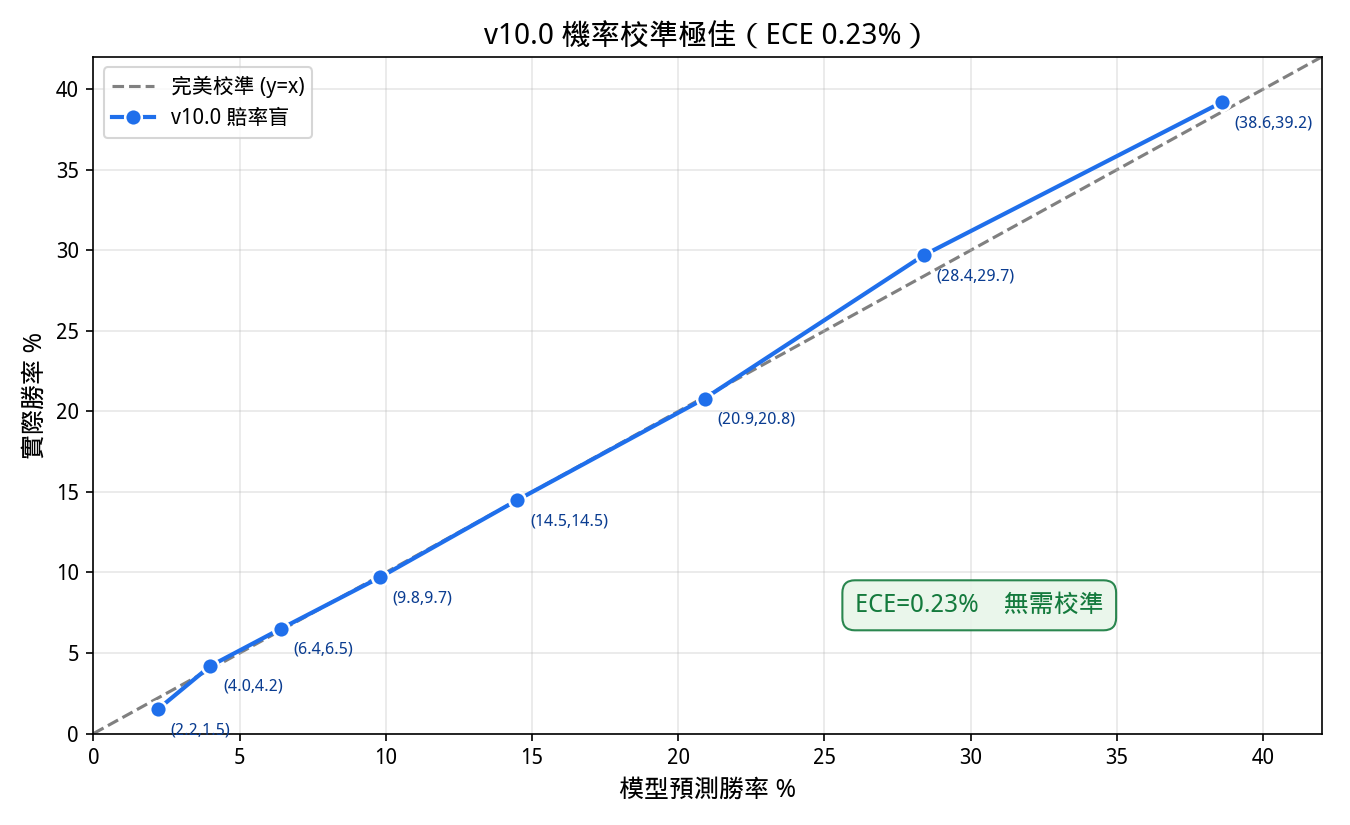
圖 2: 可靠度曲線;八個機率分箱的預測機率對實際勝率近乎落在對角線上,期望校準誤差僅 0.23%。
6. 結果三·價值與市場效率
校準既已排除,問題收窄為:一個校準良好的賠率盲排名器,能否據其「價值」(期望值)作出有利可圖的投注?本節以歷史獨贏賠率作防洩漏回測(value_backtest.py,於乾淨保留 C+D+E 平注每注一元),結論是斬釘截鐵的否定。
| 機率下限 | 期望值≥ | 注數 | 勝率% | 投資回報率% |
|---|---|---|---|---|
| 0.00 | 0.00 | 7540 | 3.06 | −37.5 |
| 0.05 | 0.00 | 4274 | 4.54 | −33.6 |
| 0.10 | 0.00 | 1776 | 6.98 | −34.9 |
| 0.20 | 0.00 | 296 | 12.50 | −23.5 |
| 0.20 | 1.00 | 72 | 11.11 | +2.8 |
| 0.35(保守方案甲) | 0.15 | 6 | 0.00 | −100 |
按賠率帶觀察冷門高期望值(全窗、期望值≥1.0)的問題亦已解決:
- 賠率 [1, 8):n=12,勝率 25.0%,回報率 +85.8%(樣本極小)
- 賠率 [8, 20):n=320,勝率 3.4%,回報率 −59.8%
- 賠率 [20, 999):n=4660,勝率 1.1%,回報率 −48.4%
結論:投注模型的「價值」/期望值玩法在幾乎整個格點上皆虧損。 那些在期望值排名上看似誘人的高期望值冷門,正是冷門陷阱——它們蝕 48% 至 60%。模型平均而言校準良好,但當它與市場強烈分歧時,市場是對的(後段資訊:配備、晨操、資金流向)。唯一接近打和的角落是高信心×高期望值(機率≥0.20 且期望值≥1.0:+2.8%,n=72),樣本太小、噪音太大,不可信賴。
根本原因是設計使然:模型按三腳架獨立性而賠率盲;香港市場高效且抽水約 17% 至 18%。一個賠率盲模型是出色的獨立排名器,卻無法擊敗它拒絕觀看的那個市場——這與 Benter 一致,他那套有利可圖的系統把公眾賠率作為主導因子納入其中。要有利可圖地投注,必須把市場賠率折入模型(Benter 式),而這會打破賠率盲三腳架。
因此模型應如此使用:作為三腳架的排名器與決策支援(首選校準良好,約 23% 勝 / 50% 位)為其本分且勝任;不可作為獨立的價值/投注引擎;期望值與市場賠率欄保留為資訊(模型與市場的分歧處=該深思、該由 Eric 判讀之處),而非下注信號。
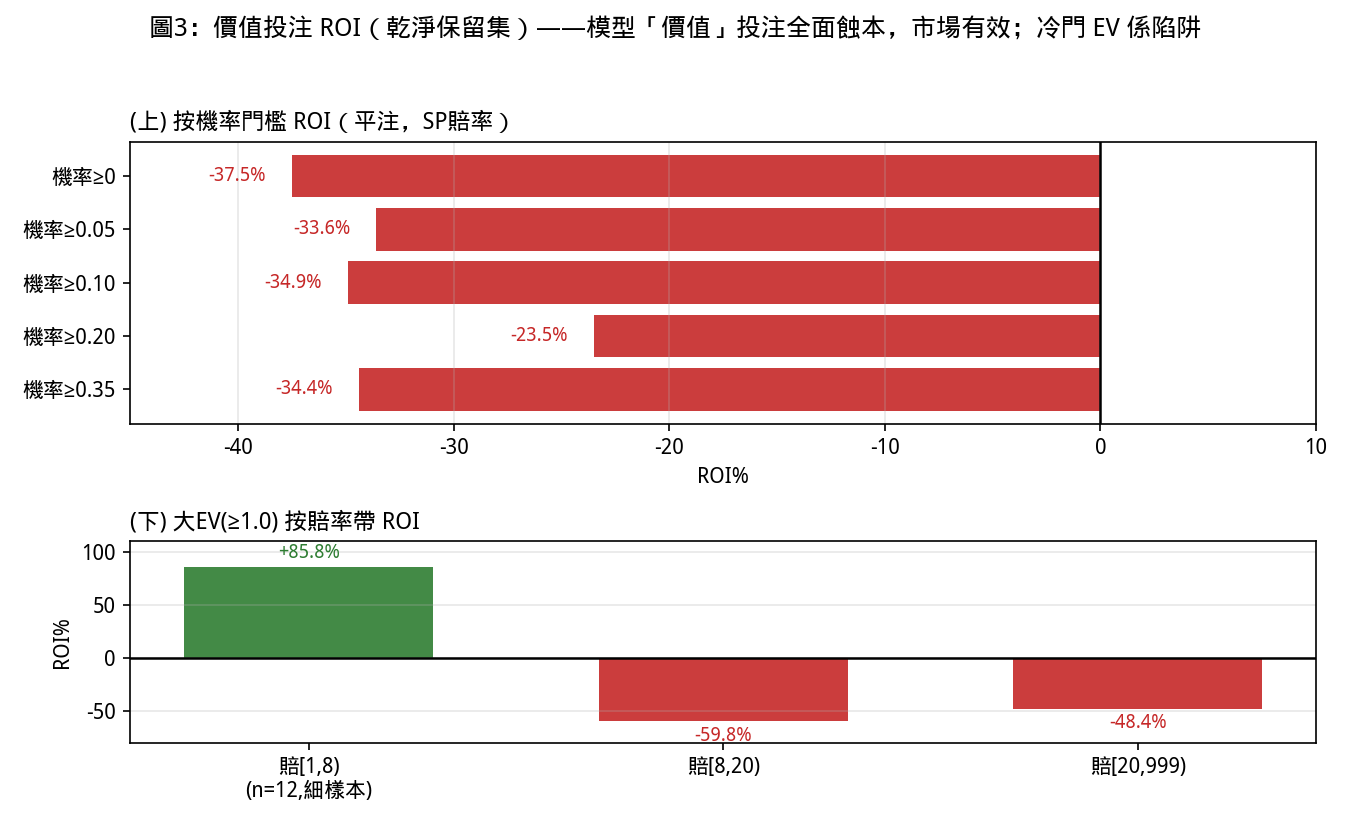
圖 3: 各賠率帶的投資回報率;除樣本極小的低賠率帶外,冷門帶深陷負值(蝕 48% 至 60%),印證冷門陷阱。
7. 結果四·Benter 第二階段
第 6 節已指出,唯一被證明能擊敗市場之路是把賠率折入模型。Benter 的致勝系統正是兩個模型:第一階段為基礎的賠率盲模型(本系統=V10.0),第二階段為一個組合邏輯回歸,融合基礎機率與公眾賠率機率:combined_i ∝ exp(β1·ln p_fund_i + β2·ln p_public_i),場內歸一化指數,β1、β2 由保留場以條件邏輯回歸最大概似擬合。Benter 的邊際在於 β1 遠大於零——他的基礎模型承載了群眾錯失的資訊。本節以開關式架構(stage2.py)建立此層並實證檢驗 V10.0 是否具此邊際。
在一組窗擬合 β1、β2,於另一組互斥窗測試(兩個獨立切分):
| 擬合 → 驗證 | β1(基礎) | β2(公眾) | 保留集期望值≥0 回報率 | 95% 信賴區間 |
|---|---|---|---|---|
| C+D+E → A+B | −0.167 | +1.193 | +31.1%(n=47) | [−28, +93]% → 不顯著 |
| A+B → C+D+E | −0.195 | +1.146 | −37.7%(n=53) | [−74, +10]% → 不顯著 |
保留集對數損失(A+B):基礎單獨 2.299、公眾單獨 2.039、合併 2.036。
兩個明確無誤的結論:
第一,β1 在兩個切分上皆約等於零(且為負),意即 V10.0 對市場無任何增量——公眾賠率已知的,它一概沒有額外補充。合併模型本質上約等於公眾(對數損失 2.039 降至 2.036,僅 0.1% 的微動);公眾是遠比本模型銳利的預測器(2.04 對 2.30)。
第二,那個搶眼的 +31% 保留集回報率是噪音——其信賴區間大幅跨越零,且切換切分即翻成 −38%。這是典型的小樣本海市蜃樓(47 個邊際注),在更高期望值門檻下先塌成 1 注、再塌成 0 注。
原因與整個過程一致:Benter 的 β1 強烈為正,因其數百因子的模型找到了群眾錯失之物;本系統五特徵的基礎模型尚不夠精密,高效的香港市場(加約 17% 至 18% 抽水)早已定價其所知的一切。第二階段的開關架構雖屬健全(ENABLED=False 預設關閉、可即時切換、不需重訓、第一階段不受影響、三腳架完整可重現),但只應在第一階段獲得真實正交邊際時——即重擬合的 β1 在保留集上明確大於零時——方可開啟。在此之前,開啟它只會把排名推向市場熱門並輸給抽水。預設:關閉。
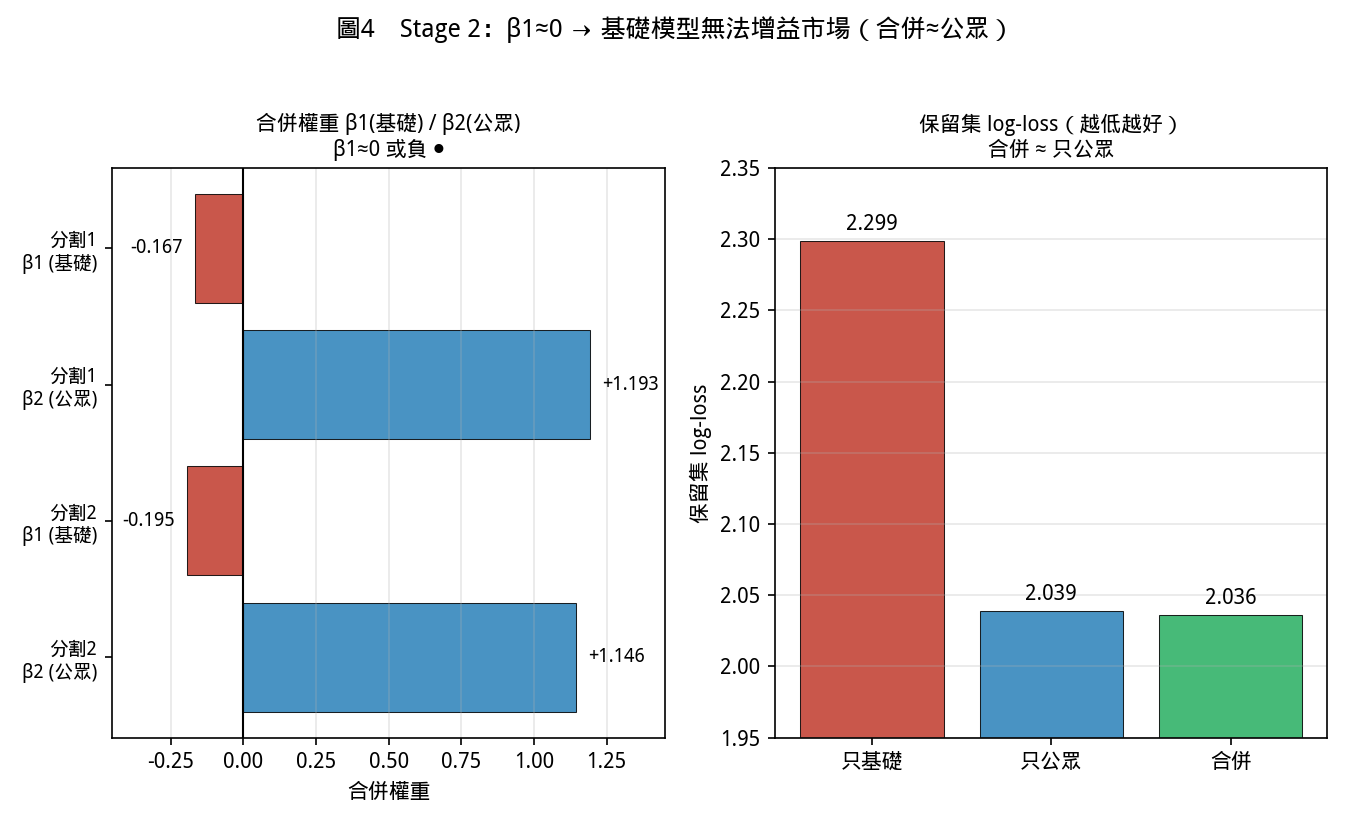
圖 4: 兩個獨立切分的 β1 皆約等於零(且為負),合併模型的對數損失幾乎等同公眾單獨,證 V10.0 相對市場無正交增量。
8. 討論與結論
8.1 V10.0 是「賠率盲+簡單特徵」這一類的天花板
四項結果指向同一個收斂的判斷。特徵層(第 4 節):七個簡單加性特徵全數被否決,在目前樣本外解析度下無一能擊敗 V10.0。校準層(第 5 節):模型已校準良好(ECE 0.23%),命中率無校準可改。投注層(第 6 節):賠率盲模型的價值投注幾乎全盤虧損,冷門陷阱蝕 48% 至 60%。市場增量層(第 7 節):β1 約等於零,模型相對市場無增量資訊。
合而觀之:V10.0 已是「賠率盲+簡單特徵」這一整類模型的天花板。 它是一個校準良好的優秀排名器,卻不是市場擊敗者;繼續單特徵研磨只會不斷抬高假陽性風險,而不會帶來真實邊際。逐特徵研磨應就此停止。
8.2 戰略岔路
餘下的真實提升空間不在更多特徵,而在兩條岔路之間的抉擇——這是一個設計決定,而非研磨:
岔路一·更豐富的 Stage 1。 唯一被證明能擊敗市場之路,是一個資訊上更豐富的第一階段,其重擬合的 β1 在保留集上明確大於零,再透過第二階段把市場賠率折入投注輸出。這正是 Benter 之路,但它刻意放棄賠率盲三腳架的投注輸出端。這需要的不是又一個簡單特徵,而是質的飛躍(更多、更銳利的因子)。
岔路二·運營化。 接受 V10.0 為簡單特徵類的近最優解,把資源轉向運營:預測網站、賽後認證(results-certify 紀律與分歧日誌)。這條路不嘗試擊敗市場,而是把已有的優秀排名器與三腳架決策支援落地、並建立持續監測與認證的閉環。
8.3 誠實負面結果的價值
本篇通篇是負面結果:0/7 特徵、校準無助於命中率、價值投注虧損、β1 約等於零。但這些負面結果本身極具價值。第一,它們封閉了死路——若無演進後的紀律閘,海市蜃樓特徵(draw_eb、trip)早已上線,並把窗特定過擬合偽裝成進步;若無配對顯著性檢定,closer_turns 的 +0.26pp 早已被誤收為「首個正面結果」。第二,它們重新定位了瓶頸:對抗性審查證明真正的瓶頸是測量而非模型,逼出了配對逐場信賴區間閘,這道閘的效力遠勝原始聚合比較。第三,它們把資源從注定無功的方向上釋放出來:明知簡單特徵已飽和、明知賠率盲無法擊敗市場,戰略抉擇便能聚焦於真正有槓桿之處,而非在雜訊底之下繼續徒勞研磨。
寧可記下一個誠實的負面結果,也不可賣一個會蒸發的數字——這是 V10.0 基礎篇立下的紀律,本篇以七個被否決的特徵、三項決定性實證,將它貫徹到底。
9. 參考文獻
- Benter, W. (1994). Computer Based Horse Race Handicapping and Wagering Systems. In Hausch, Lo & Ziemba (eds.), Efficiency of Racetrack Betting Markets.
- Bolton, R. N., & Chapman, R. G. (1986). Searching for Positive Returns at the Track: A Multinomial Logit Model. Management Science 32(8).
- Harville, D. A. (1973). Assigning Probabilities to the Outcomes of Multi-Entry Competitions. Journal of the American Statistical Association.
- Brohamer, T. Modern Pace Handicapping.
- racing_engine 內部文件:
V10.0_whitepaper.zh-HK.md、GRIND_ROADMAP.md、V10.1_RESULTS.md、V10.2_RESULTS.md、V10.3_RESULTS.md、V10.4_RESULTS.md、CALIBRATION_AND_VALUE.md、STAGE2_FINDINGS.md、registry 及窮舉掃描原始數據。
數據來源:racing_engine 配對CI閘(乾淨保留 C+D+E)+ 校準/價值/Stage2 回測;全部已 git 提交。